
Announcing posetree.py: Wrangling Timestamps and Transforms for Robots
So You Want to Do Robots: Part 11

About this series
I’ve been working on general purpose robots with Everyday Robots for 8 years, and was the engineering lead of the product/applications group until we were impacted1 by the recent Alphabet layoffs. This series is an attempt to share almost a decade of lessons learned so you can get a head start making robots that live and work among us. Previous posts live here.
What is posetree.py
There is one library I’ve written that is so important to my productivity and sanity I wouldn’t bother working on robots without it. It’s called posetree and it's a library for dealing with poses and transforms. It makes whole classes of super common bugs impossible, robotics code more readable, and frees precious brain cells from fiddly boring stuff. With it, you can spend more time thinking about the real problems you’re trying to solve. So I wrote this open source version so everyone can use it. You can jump right to the API on the GitHub page, or keep reading to learn why I think this is a better way to think about poses.

Not this kind of pose.
Wait, what's a pose?
In case your experience in robotics is more casual: a pose is a way of describing the position and orientation of things. If you have a robot and it sees a person it needs to avoid and also a table it needs to clean; all that information can be represented by poses. (A pose for the robot’s location, one for its camera, another for the gripper, one for the person, and one for the table).

Also in robotics things move around, so it matters when we saw the person there. Roboticists spend a ton of time thinking about where objects are, (and were), and especially a ton of time debugging these things. One of my favorite quotes sums it up:
“All of robotics is just timestamps and transforms” -Chris Mansley
Names Matter
Some robotics codebases use “pose”, “transform” and “frame” fairly interchangeably. This is a huge missed opportunity to be clear in our code and our thinking. So posetree takes an opinionated stance:
Transform: This comes from the verb, to transform. It is how you get from one place to another. It is an operation to change your location from one to another.
Example: “Take 10 steps forward and then turn 90 degrees to your left”
Pose: This is a noun. It is a physical location and orientation in 3D space.
Example: “Standing at my front door facing the street.”
Notice we can take our example pose (standing at my front door facing the street) and transform it into another pose by using our transform instructions (take 10 steps forward and then turn 90 degrees to your left). If we do that we have a new pose that is a bit in front of my house and (in my case) facing our detached garage.

We can make any pose we want by taking a starting point and transforming it. The starting points are called “frames of reference” (or just frames) and without them we can’t talk about where anything is. You can think about frames as famous poses. They are like pose celebrities. Everybody knows them.
In this sentence, “From the Target Parking lot, take the first right and go two blocks” we define a pose. The transform is “take the first right then two blocks” and the frame is “Target Parking Lot”. This uniquely describes a location and orientation.2 Which brings them to our definition.
Frame: This is a pose that is so important we’ve named it and everyone knows about it. We use them to measure where things are in reference to it.
Example: We could name “Standing at my front door facing the street” “journey_start” and then we could describe that other pose by saying, “from journey_start take 10 steps forward and turn 90 degrees to your left”
Why is this good?
It helps make it clear what information is needed for each of these things.
A transform is a change-in-position and change-in-orientation.
A pose is a transform plus a reference frame.
A frame is a famous pose with a name that other poses refer to.
Each one in the list takes the one before and one additional piece of information. Traditional robotics software often uses data-structures that only have enough information to hold a transform and uses it to represent poses and frames. So where does the starting frame information go? Into the variable name(!).
Robot code often looks like this:

Where each of those things is actually a transform object, representing a pose by storing the starting frame into the variable name before the “_t_” (which stands for “transform”). This tradition started because there is a nifty math trick where if you stuff the rotation and translation just right into a 4x4 matrix (and add an extra 1 in the right spot) you can chain transforms together by multiplying the matrices.3 But this is error prone and it's easy to get the order wrong because matrix multiplication is not commutative (A*B != B*A) so the naming convention helps because you can look and see that the words next to each other are the same.

But the fact that we can calculate transforms via matrix multiply is an implementation detail. We don’t have to structure our code and variable names to carefully multiply matrices just right. That's what computers are for.4 That's why in posetree, poses contain their defining frame as part of the data.

No really, why is this better?
Because poses know their frames and have a reference to the transforms between all the current frames, they can do math across frames automatically.
Here is an example:

Those poses are defined in different frames. To do this without this library looks something like:
distance_from_person_to_charging_bay = np.linalg.norm(get_translation(world_origin_t_charging_bay.inverse() * world_origin_t_robot * robot_t_camera * camera_t_person))5
If this small example seems tricky, I guarantee you it gets a lot harder. And every roboticist has made the mistake of getting the order wrong or forgetting an inverse.6
Show me more things it can do!
Sure thing!
Let's get a set of potential pre-grasp poses that are in a 50 cm ring around a bottle with z pointed inwards. The bottle comes back with a pose where it’s z points up.


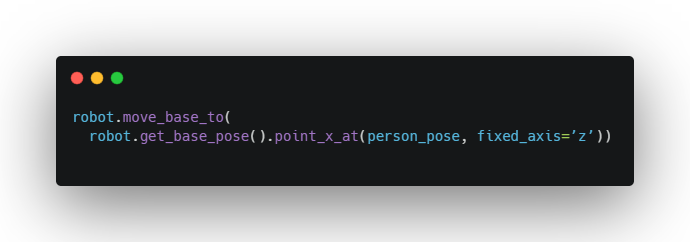
Lets point the robot base at a person:
We’ll take the current pose, and rotate it about z to have the x-axis point at person pose. What frame is person_pose in? I don’t know and I don’t care.
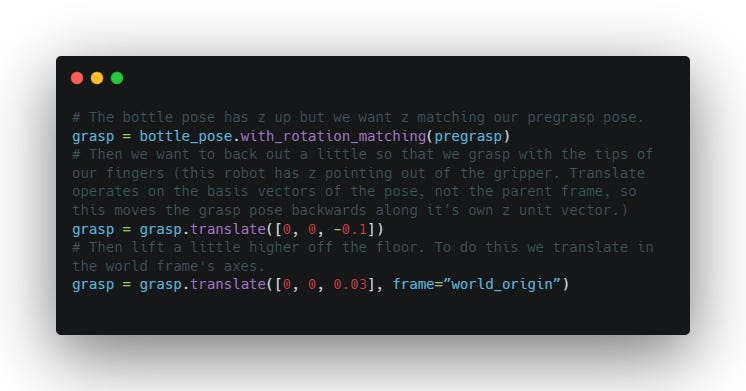
Lets carefully construct a grasp pose:
But the big win is the “timestamps” part
Because a pose represents a place relative to another frame, and frames move all the time, and the pose_tree is aware of that motion, you can express very powerful ideas with simple code.
We expect a lamp to stay stationary relative to the world, so we’ll store its pose in that frame. We’re also careful to convert from the camera frame (were we detect the lamp) into world frame at the camera-shutter timestamp, so that even if the robot is moving and we get the detection message after a bit of delay, our telemetry data and perception data are synced and the lamp is fixed to the outside world exactly where we saw it.

Under the hood, look_at will call lamp_pose.in_frame(“robot”) to figure out where the lamp is relative to the robot and calculate the angles needed to move the head to look at it, even though the robot has moved away since we observed the lamp.
In general you can use the parent_frame of a pose to ‘glue’ it to something; like the robot’s base, the world or even the tool. For example:

If you’ve read this far you should check out the readme and documentation because I worked, like, really hard on it. And if you’re working on a robotics project, try integrating it and let me know how it goes!
Thanks to Ryan Julian and Jeff Bingham for reading early drafts of this and for getting philosophical about poses with me many times over the years.
And, I have to say, 6 months of working on whatever interests me has honestly been fantastic. 10/10 would be laid off again.
There are many Target Parking lots in the world but as long as both people know which Target they mean, they can use it as a frame. Just like there are many robots and cameras in the world, but code can use ‘robot’ and ‘camera’ as frames because its clear from context what those two frames are. Unless there are multiple cameras or robots, in which case you’d need more specific frame names.
(IE, if you have one matrix that represents “walk forward 10 steps then turn around” and another that represents “walk forward 3 steps and turn left” if you multiply those together you’ll end up with “walk forward 7 steps and turn right” which is the result of doing those two thing).
Math is hard, let's go watch the Barbie movie.
And we see our “make sure the words next to each other match” rule is already falling apart because we needed charging_bay_t_world_origin but we only had world_origin_t_charging bay so we use inverse() which swaps it at the cost of our rule. Of course you could create a local var to hold the inverse each time you need it, but in practice folks prefer the brevity.
If this small example seems tricky, I guarantee you it gets a lot harder. And every roboticist has made the mistake of getting the order wrong or forgetting an inverse
“All of robotics is just timestamps and transforms”
I believe that quote can be attributed to Chris Mansley.