
ML for Robots: Hybrid Learned vs End-to-End Learned
So You Want To Do Robots: Part 6

About this series
I’ve been working on general purpose robots with Everyday Robots for 8 years, and was the engineering lead of the product/applications group until we were impacted1 by the recent Alphabet layoffs. This series is an attempt to share almost a decade of lessons learned so you can get a head start making robots that live and work among us. Previous posts live here.
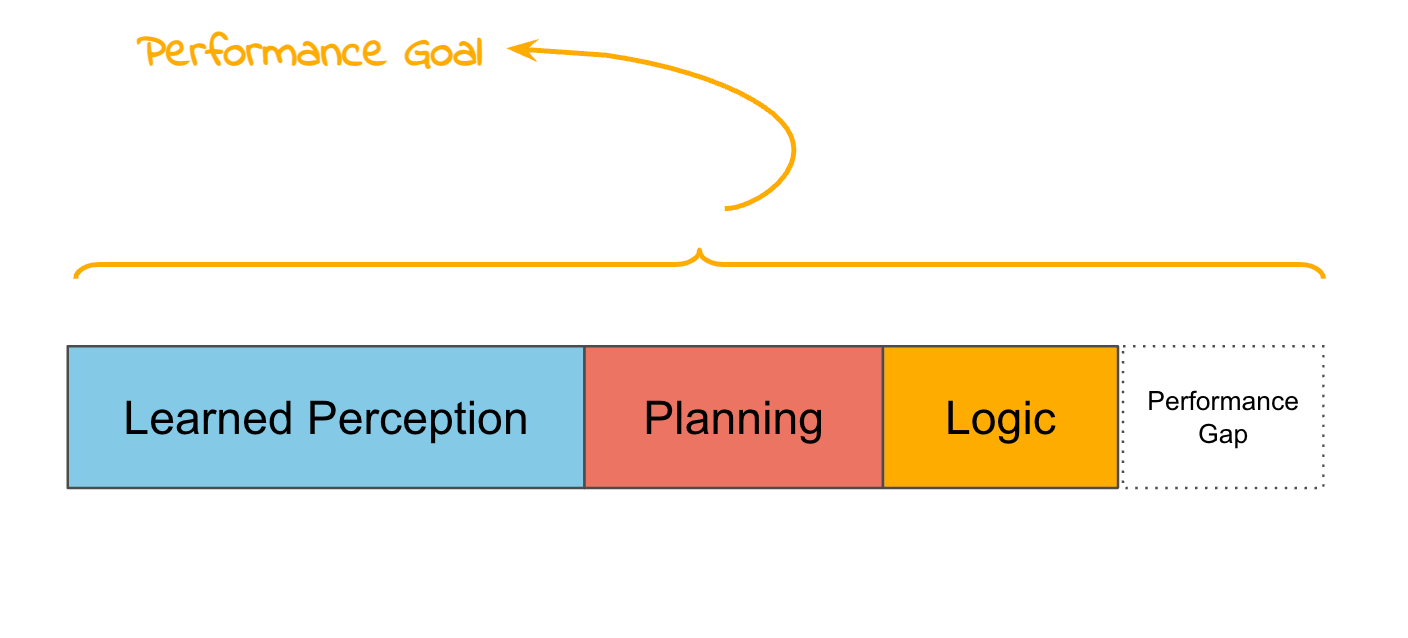
ML perception works well: Just use it
This essay is about how and when to use “ML” but I’m going to be loosey goosey with my definitions. Using deep convolutional neural networks for perception is just a good idea. And it would be kind of weird to use classical computer vision to do object detection or segmentation in 2023. So in the grand tradition of AI, I will be using “ML” in this post to refer to just the ML that doesn’t work super well yet: specifically using the output of neural networks to change the way that robots move in an attempt to solve the dexterity problem.
Why use ML at all? A Game of Whack a Mole.
When you first script a new task, things usually come together very quickly. Say you want to clean empty bottles off of countertops. By the end of an afternoon you have the robot doing the task pretty well.2 When everything goes just right, it works and it seems like you are almost done.3

But then you notice that sometimes another bottle is too close and the robot bumps it. So you put in a check: “If there is a bottle next to the bottle I’m grasping, grab the bottle from the top, not the side”. That fixes the problem you saw. Performance is a little better, logic a little larger.
But our tale of woe is not complete, because a few minutes later a bottle is close enough to trigger your new “top-grasp” behavior but the robot can’t reach the top from where it's standing.4 And actually, it would have been fine to do a side grasp, so your new logic made things worse. So you add a special-case so if the robot can’t reach the top you shrink the threshold so it's more willing to side grasp near bottles. At this point you’re starting to really understand the engineering expression “you do the first 80% of the work and then you do the second 80%.”5

Each time you add code to cover an edge case, you end up with two smaller edge cases, and your code gets more and more complicated and harder and harder to test. And eventually it gets to the point where you know you are making things harder to debug but you can’t even tell if performance is getting better. We call this “robotics whack a mole”.
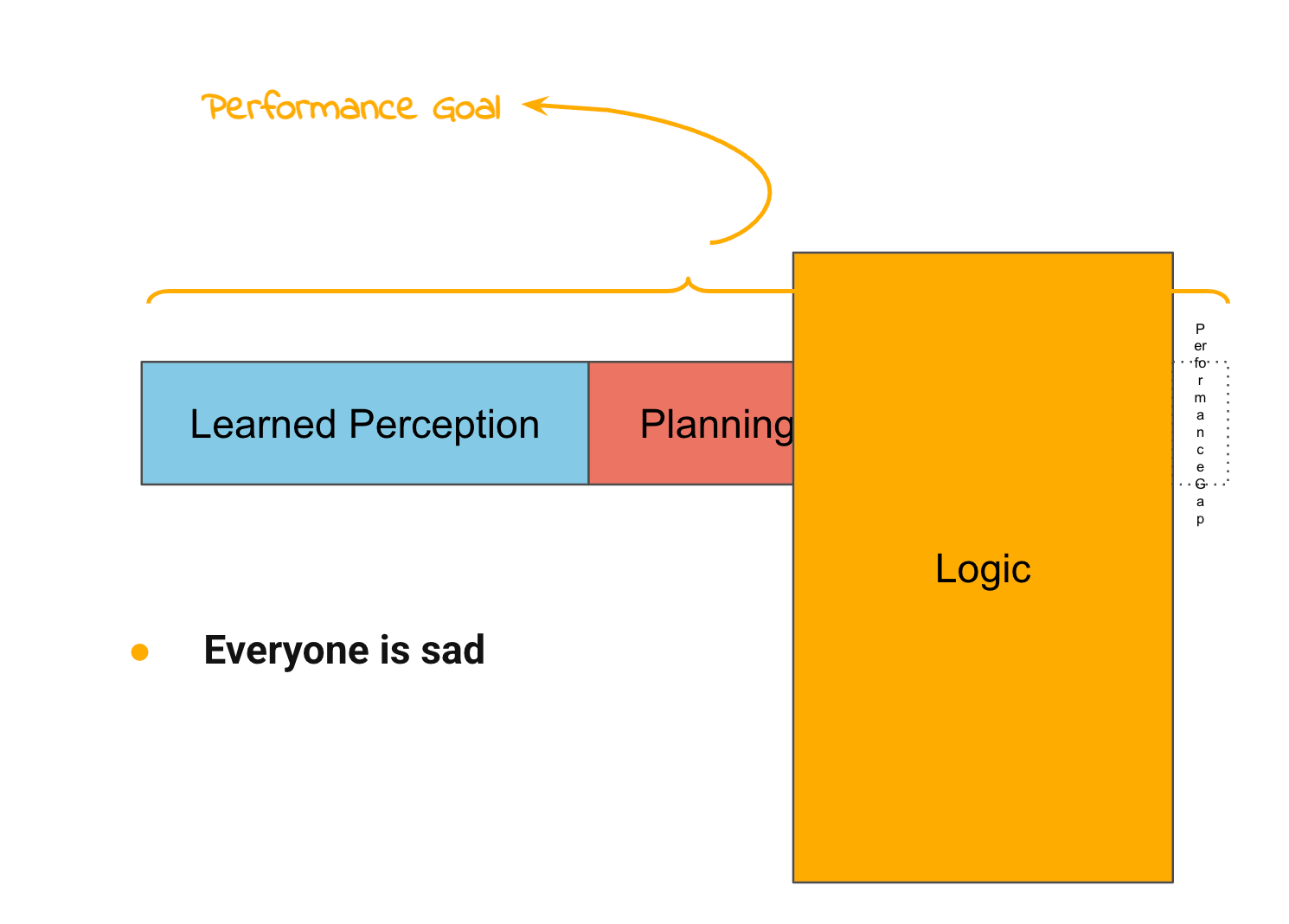
So, having experienced this, roboticists have fairly universally decided that we hate it, and that it would be great if someone could use ML to make this problem go away.
Two philosophies of ML for two different goals
Having arrived here together, folks have different ideas of what the root of the problem actually is, what the goal is and therefore what we should do about it.
Group One: General Intelligence Enthusiasts
The first group believe robotics whack-a-mole is so awful we should stop ever trying to program robots. Especially if you want a robot that can respond to any request you make, there is no way to program all of those behaviors.
“Hey robot, can you make me a vanilla soy latte in my cat-butt mug and add a curly straw?”
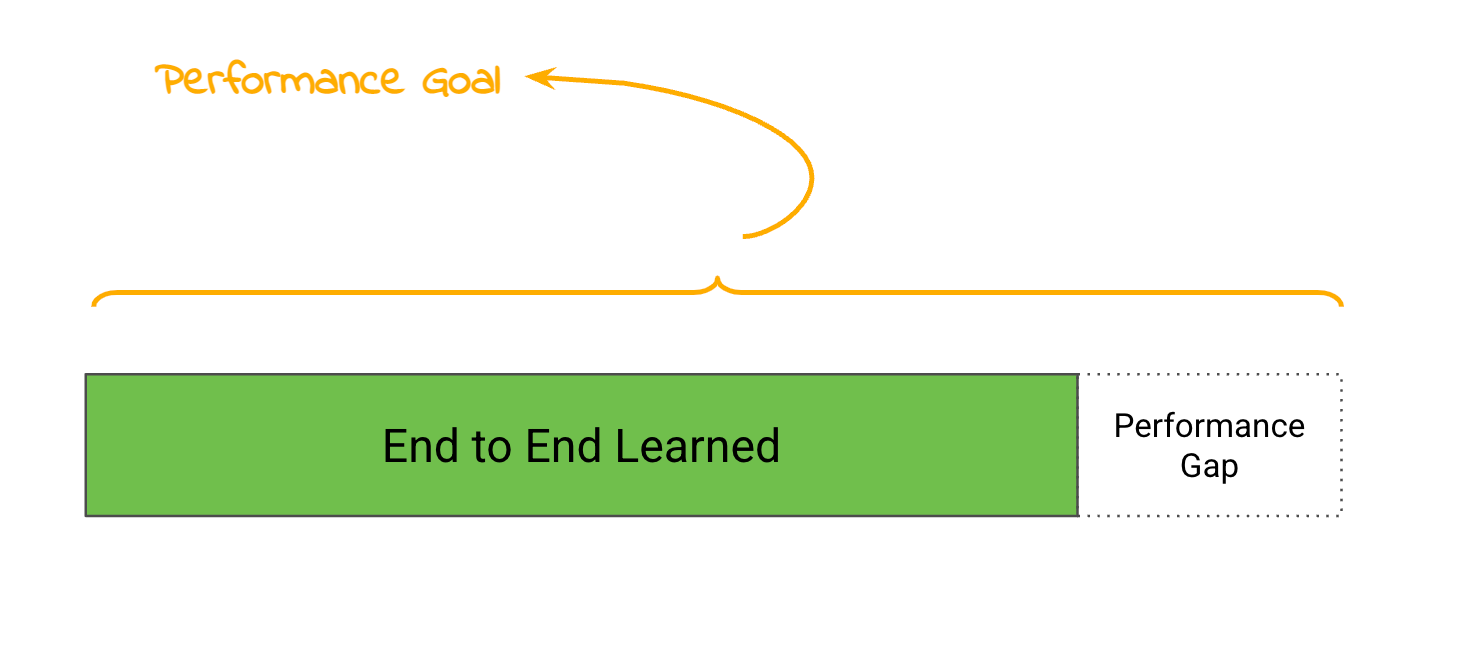
If people are allowed to ask the robot for basically anything, then the only reasonable solution is to end-to-end learn how to do stuff. Things like ChatGPT and Stable Diffusion show that, in some cases, we have created ML models that can respond to basically any spoken request.6
Also, folks have read the Bitter Lesson which says that when you try and encode your knowledge of a problem into ML you might get short term gains but a research dead end. This is because in the long term, simpler, more generic models win if you can shove a large enough mountain of data at them. Which you can eventually do, because computers get faster and cheaper all the time. Knowing this, artificial intelligence enthusiasts are generally more excited about more generic, end-to-end approaches.
No-code is probably a requirement for this kind of generality in the finished state, but you still need some way to collect your initial data set to bootstrap the whole dang thing. So the process looks something like this:
Find some way (eg scripted “80% solution”, human teleop or something more exotic) to create your first set of training data. You’ll also need to invent a universal set of inputs and outputs that you think can solve any problem.7

Start running your end-to-end model to power your robots and collect more data.

Which lets you retrain on better data, improving performance.

Goto step 3


The problem with this approach, for a startup, is that it's still firmly in the realm of research and it's hard to know how much data it's actually going to take.
But folks have done some truly impressive things with end to end techniques.
Group Two: Jaded Pragmatists
The second group (which includes me) sees the problem as occurring when the increasing complexity stops buying you increasing performance. We don't care if our ML lets robots respond to any requests ever, just that we can use it to make robots do some things really well. Multi-purpose is good enough, it doesn't have to be all-purpose. We want ML so that if the robot does something dumb we can say "oh, just wait and the ML will fix that over time" rather than having to write code to fix the bug.

“Using the power of AI we have discovered a whole new class of bug we can close: ‘won't fix’”
The way to do this kind of ML is to build the conventional solution and then try and improve it over time. When you notice a heuristic growing in complexity, that is a good sign that you can replace it with some ML.

And then collect more training data and let it improve over time.
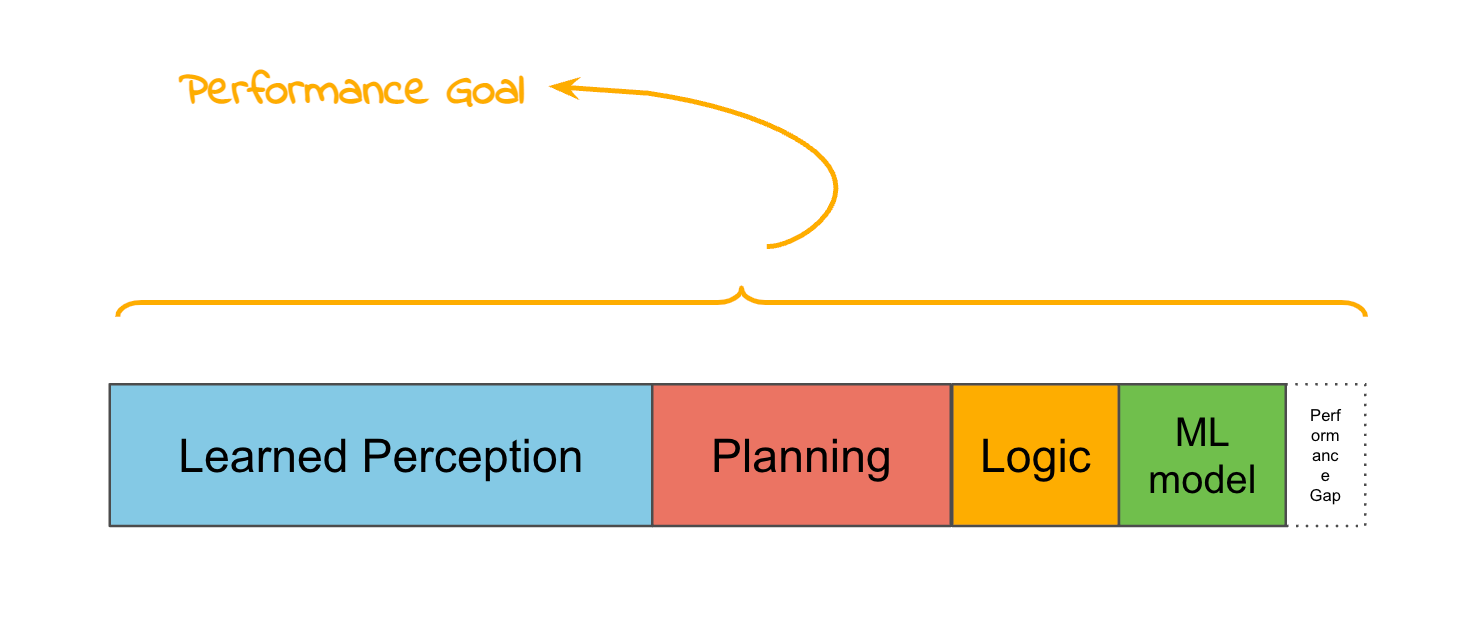
I get tired of saying “Learned perception plus planning & logic and a small task-specific ML model” so I’m going to call this combination of stuff “Hybrid Learned” because it is a hybrid of classical techniques and learned techniques.
Examples of specialized ML:
choosing a grasp point on an object
choosing where a robot should put its base to give it the best chance of success
choosing between a few different strategies for something

This looks like a ‘top-grasp’ kind of ice cream cone
The risks with this approach are that you are cutting out possible solutions. If you limit your ML model to choose top grasps it can't ever find a side grasp even if that would be best. On the other hand it does seem like folks are able to make things work with way less data, which is pretty compelling if you are paying for the data with your runway.
What to do if you want to do fully general robot ML
At Everyday Robots we did quite a bit of end-to-end learning. I think it's fair to say that this is near the cusp of working well. We certainly got it to do things (grasping trash, opening doors, and later sorting trash). But it takes a mountain of data to train (for trash sorting we had millions of sim examples plus months of 30 robots sorting trash all day long in a lab8). And every project we tried started with the expectation of taking a month or two at most and actually taking several years.

“But next time it will only take a few months, I promise.”
In the end, the data hunger of these techniques make them really hard to work with. You can get the scale in sim, but then you will train an agent that does simulated work really well, and likely fails utterly on your real hardware. Even the small differences between the lab (where we did data collection) and the real world trashed9 the in-the-wild success rate of our garbage sorting robots. The breakthroughs happening in this area are really cool, and the people are very smart, but the problems are really hard.
So here is my advice: if this is what excites you, don’t do a startup. You want to find a patron to pay you to make breakthroughs. Choose something like a University or a big-tech-co R&D lab or a Florentine Duke.

“Yes, I’m commissioning some reinforcement learning algorithms for my nephew. As a wedding present.”
You don’t want to try to raise a bridge round because you burned your runway doing research and you can tell you’re almost there but nothing really works still.10 Instead, find a way to do the research on someone else’s dime, and then, if you make the breakthrough you are hoping for, publish, quit, and start your startup. End-to-end techniques will continue almost-working until all of a sudden they do work. I’m not going to bet against that happening, but I’m also not going to bet on that happening exactly when I need it to save my business.

“OK, in April we raise a seed round, in May we make a major breakthrough in ML for robotics and then in June we use that sell the 50,000 robots we just ordered from our manufacturer.”
What you want to do if you want to ship a product as soon as you can
Remember you are complexity limited. It's easier and faster to write code than use ML for most things. Be careful and strategic about where you add ML because ML is going to take more time than you think. Look for places where your heuristics are growing out of control as good candidates. Try to find ways to reframe manipulation problems as perception problems because perception works.

Maybe you can detect grasp features rather than predict grasp poses and that works well enough.
Work to speed up iterations is time well spent. You are going to need to iterate more than you think, and doing that earlier would have helped us make progress faster at Everyday Robots. Can you make it easy to reformat your data in a different way? To train, and eval? How fast can you make it?
And the Bitter Lesson applies to you too. The most important takeaway is that you can get performance gains in the short term by encoding your knowledge (by simplifying or structuring the ML problem, usually by reducing dimensionality11). You're in a startup: you are all about short term gains. But you should be ready for researchers to unlock new, more performant, recipes. That means you should keep all your data around, if you can, and be ready to retool your ML if the state-of-the-art shifts under you.
But my biggest piece of advice is to push the combination of ML perception plus classical robotics as far as you can, because I bet there are a bunch of businesses where you don't need new ML breakthroughs to make things work.
And now on to part 7!
Big thanks to Michael Quinlan, Mrinal Kalakris and Ryan Julian for reading drafts of this, showing me new ways of looking at things and introducing me to the Bitter Lesson.
And, no, I can’t comment on any of the news articles about Everyday Robots (at least until my severance check clears.)
Remember the first rule of robotics: as soon as it works, get a video.
Ha ha. lol, no.
To sound more impressive to your roboticist friends, you can say, “doesn’t have kinematics for a top grasp”. And then you can wander off muttering about “the damn morphology having bad manipulability in that kinematic regime” and people will assume you’re super smart. That's a pro tip.
For robots it’s really an open question how many “80%”s there are. At least 5.
Though not perfectly, yet. This is the first response Stable Diffusion gave me for “a man wearing a fox for a hat”

Example universal inputs: camera images and robot gripper positions. Example Universal outputs (or "action spaces" if you want to sound like you have a PhD): small displacements for the tool or base. The tricky thing is how you handle force feedback on your actions (do you put stiffness or force saturation or stop-on-contact etc). Of course the most universal outputs would be motor torque, which is why folks often call this kind of universal ML "pixels to torque" but torque is a hard thing to learn. So while there are examples, it's not commonly done.

see what I did there?
For reals, though, you can’t tell if you are almost there, which is more dangerous. It always seems like if you had just a little more data/training/model refinement it would all fall into place.
Example: Instead of learning a whole grasp trajectory (6 joint positions x 25 time steps= 150) You could just learn a top-grasp point (x, y, rotation = 3) if you know that a top grasp will likely be good enough for your task.
Thank you for writing such an insightful and lucid post!! As a robotics researcher, I’ve often found during implementation that hybrid approaches give me the best bang for my buck, but there’s so much excitement about pure end to end ML in robotics these days, that I often wonder if I’m just doing things wrong. It’s very interesting (and sobering!) to read about what you’ve found from having worked on this stuff for 8 years; perhaps hybrid systems deserve their own serious research agenda in addition to all the pure end to end ML :)
Hi Benjie,
Did you see or anyone use old school Bayesian logic in robotics, like decision under uncertainty type (calculating utilities and such). I wondered whether they are useful or not for some type of problems.